
What is K/V Context Quantization and why does it matter?
I recently learned that Ollama added K/V context cache quantization to their models. This upgrade is a game-changer. It slashes vRAM usage dramatically, enabling you to expand context sizes or run larger models—without needing more powerful hardware.
But let’s break it down. What exactly is K/V quantization? And why should you care?
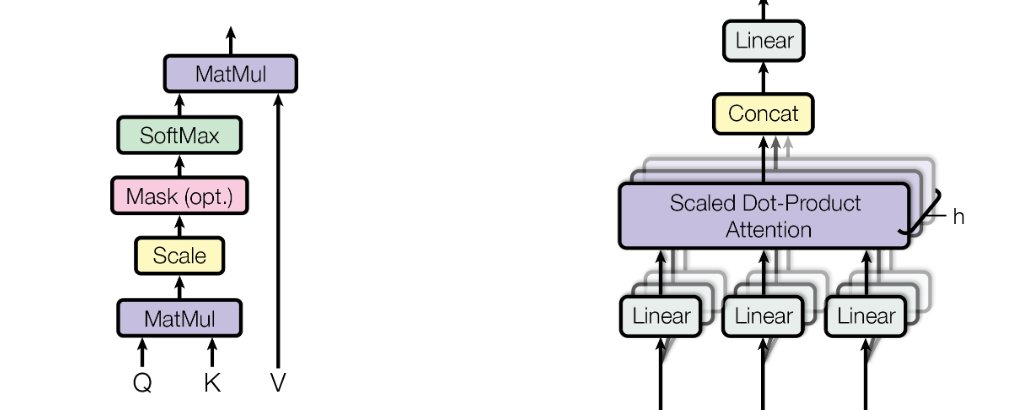
K/V Context Cache
Imagine the K/V (key-value) context as the “working memory” of an LLM. Every time you interact with the model, it uses this memory to keep track of your conversation.
It’s essential for generating coherent responses. But here’s the catch: this memory can grow huge. We’re talking gigabytes. That’s where quantization comes in.
What Is Quantization?
Quantization is like smart compression. Instead of storing every number with ultra-high precision, it rounds them off just enough to save space—without losing too much detail.
When applied to the K/V context cache, quantization dramatically reduces memory requirements. The result? You can run larger models or unlock bigger context sizes, all on your existing hardware.
The most common quantization levels are Q8_0 and Q4_0. For comparison, unquantized data is typically stored as F16 or F32 (though F32 is rarely used for inference).
Performance Impact
Here’s the best part: quantization has minimal impact on performance.
• Quantizing the K cache can slightly boost performance.
• Quantizing the V cache might cause a tiny dip.
But overall, the performance trade-off is negligible—especially when you consider how much memory you’re saving.
Compatibility
K/V quantization relies on Flash Attention. The good news is that Flash Attention is widely supported and will likely become the default soon.
If your hardware doesn’t support it, Ollama automatically falls back to the default F16 quantization and logs a warning.
Supported Hardware
Here’s where K/V quantization shines-
• Apple Silicon (Metal): Fully supported.
• NVIDIA GPUs (CUDA): Works on all Pascal GPUs and newer.
• AMD GPUs (ROCm): Supported, but performance may vary.

Arnav Jaitly
Hi, I am Arnav! If you liked this article, do consider leaving a comment below as it motivates me to publish more helpful content like this!
Leave a Comment
1 Comments
Related Posts